
扫描到手机,带走继续看!
用手机或平板电脑的二维码应用拍下左侧二维码,可以
在手机继续浏览本文,也可以分享给你的联系人。
在手机继续浏览本文,也可以分享给你的联系人。
最近,Google的一组科研人员完成了一篇新论文:基于几何感知表征的抓取交互学习(Learning Grasping Interaction with Geometry-aware Representations),论文提出了一种几何感知编码器-解码器网络,利用几何感知表征来学习实现抓取交互。
这篇论文的作者包括:密歇根大学的前谷歌大脑实习生Xinchen Yan,谷歌大脑的Jasmine Hsu、James Davidson,Google X的Mohi Khansari、Yunfei Bai、以及谷歌、谷歌研究院的Arkanath Pathak、Abhinav Gupta。
具体效果如何呢?作者还提供了一个关于实验结果的简短演示视频:
以下,是论文主要内容的介绍:
论文摘要
学习与环境中的物体进行交互是一个涉及到感知、运动规划和控制的根本性AI问题。然而,由于存在高维状态空间、很难创建大规模数据集和很难关注到物体外观的多类变化信息(如几何结构、材质、纹理和照射度等),因此学习此类交互表征十分具有挑战性。
我们论证了物体3D几何结构是抓取交互的研究核心,并提出一种称为几何感知学习智能体(geometry-aware learning agent)的新概念。
本文的核心思想是通过3D几何学预测来约束和规范交互学习。
具体地说,本文把几何感知智能体的学习过程分为两个步骤:首先,智能体通过3D形态生成模型,从2D感知输入中学习构建当前场景的几何感知表征;然后,它通过内置的几何感知表征来学习预测抓取结果。这种几何感知表征方法利用一种新颖的无学习(learning-free)深度投影层,在几何学与交互的关联研究中起到了关键作用。
本文的主要贡献有三方面:(1)我们利用虚拟现实(VR)演示构建了一个具有丰富感知和交互标注的抓取数据集;(2)我们证明了,与基准模型相比,学习几何感知表征能得到一个鲁棒性更好的抓取结果预测效果;(3)我们也展示了这种几何感知表征学习方法在抓取规划中的优势。
实现方法
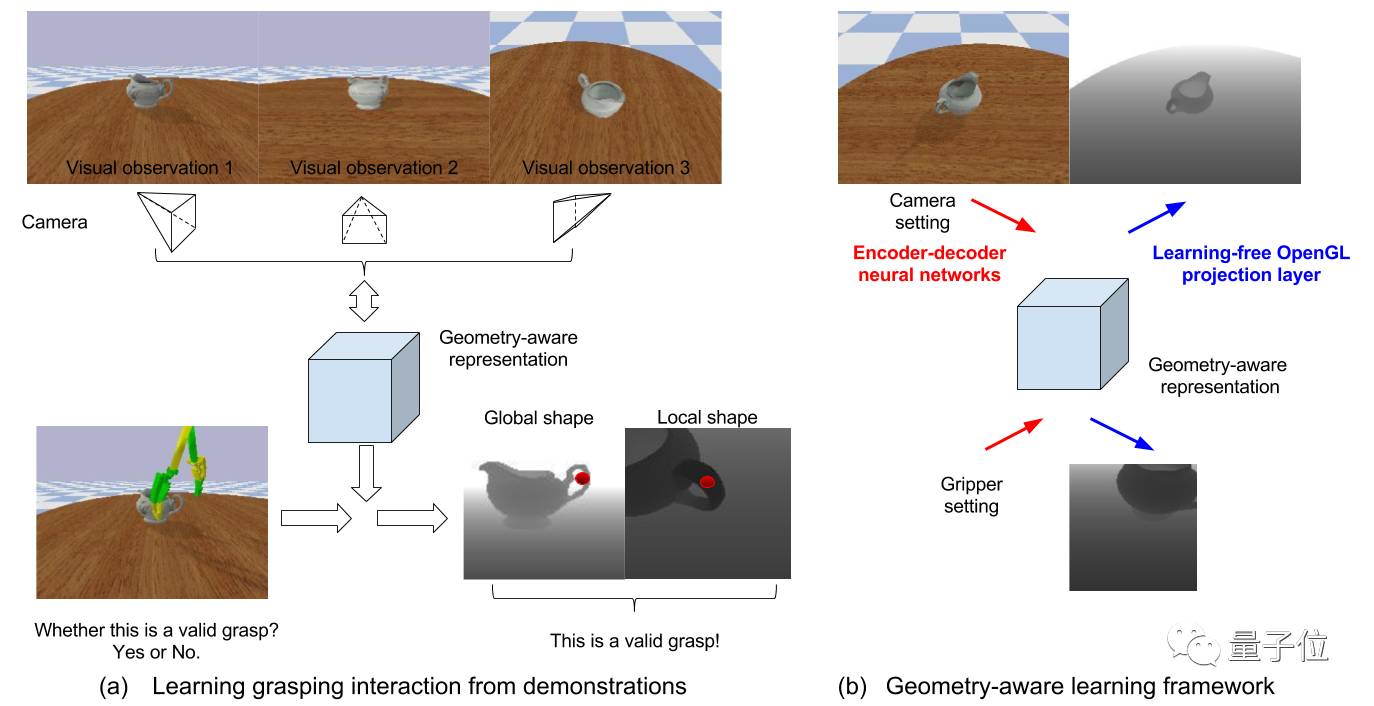
△两阶段学习框架示意图
我们提出了一种两阶段的学习框架,分别执行3D形态预测和利用几何感知表征进行抓取结果预测。给定任何场景下的2D感知输入,都能生成相应的3D物体形状(如体积表征),这是本文所提出的几何感知智能体中一个非常重要的特性。更具体地说,
在本文构想中,几何感知表征可理解为:(1)一种在世界坐标系下以相机目标为中心的场景的占用网格表征方法,和(2)其对相机视角和距离具有不变性。
模型结构
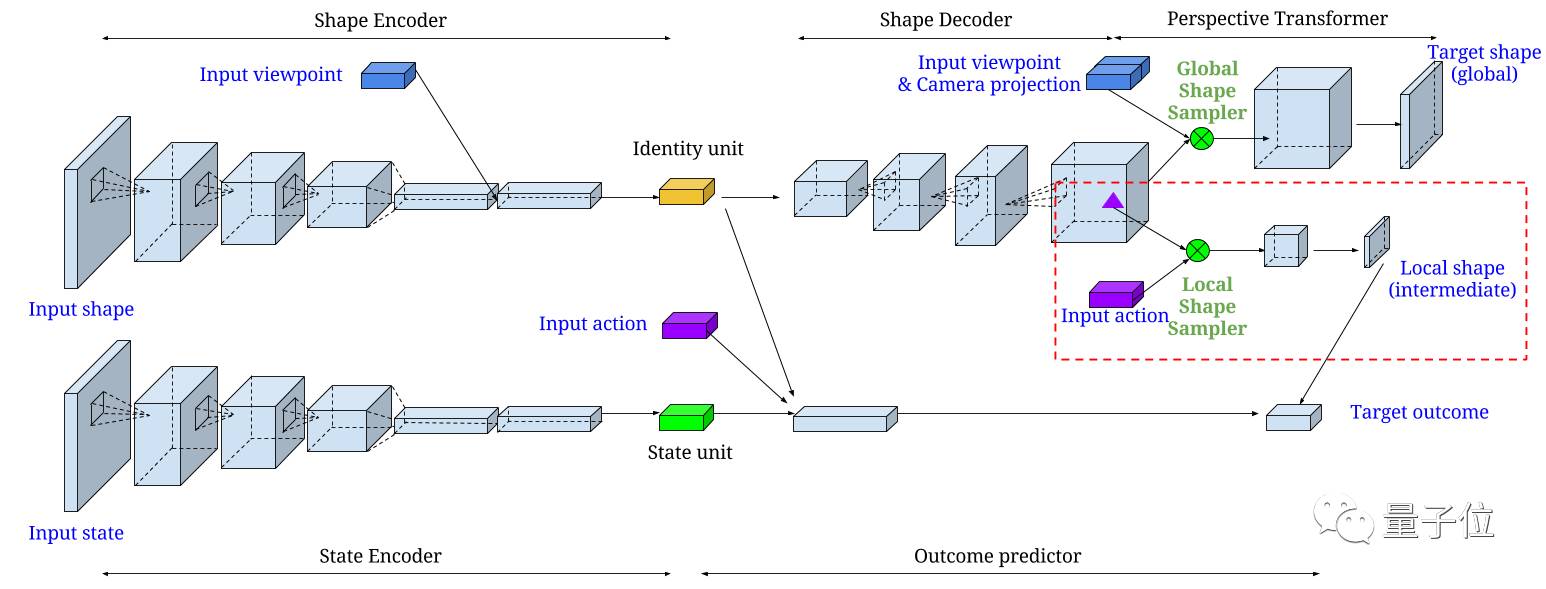
△几何感知编码器-解码器网络示意图
本文所构建的几何感知编码器-解码器网络包含两个部分,分别是3D形态生成网络(生成功能)和抓取结果预测网络(预测功能)。其中,形态生成网络包含一个2D卷积形态编码器和一个3D反卷积形态解码器,再接上一个全局投影层;结果预测网络包含一个2D卷积状态编码器和一个带有额外局部形态投影层的全连接结果预测器。
实验
下图从直观层面和内在信息流两个角度简单介绍了3D形态预测的流程图。

△3D形态预测流程图 论文传送门:









 京公网安备 11010802023289 号
京公网安备 11010802023289 号




